目标检测综述(2001-2021)
本文参考于文章目标检测究竟发展到了什么程度?| 目标检测发展22年 - 知乎 (zhihu.com)、目标检测综述_RyanC3的博客-CSDN博客_目标检测文献综述、YOLO家族进化史(v1-v7) - 知乎 (zhihu.com),编写目的为自身学习方便,不存在转载盈利等!如有问题请及时联系本人。
背景
计算机视觉问题主要分为四个方向:图像分类、图像检测、语义分割和实例分割。作为计算机视觉的基本问题之一,目标检测构成了许多其他视觉任务的基础,例如实例分割、图像标注和目标追踪等;从检测应用的角度看:行人检测、面部检测、文本检测、遥感目标检测统称为目标检测的五大应用。
目标检测算法发展脉络

传统目标检测算法
传统的目标检测算法主要基于手工提取特征。传统的检测算法流程如下:
- 选取感兴趣的区域(ROI),选取可能包含物体的区域
- 对可能包含物体的区域进行特征提取
- 对提取的特征进行检测分类
Viola Jones Detector
VJ(Viola Jones)检测器采用滑动窗口的方式以检查目标是否在窗口之中,该检测器看起来似乎很简单稳定,但是由于计算量庞大导致时间复杂度极高,为了解决该项问题,VJ检测器通过合并三项技术极大地提高了检测速度,三项技术分别为:1)特征的快速计算方法-积分,2)有效的分类器学习方法-AdaBoost,以及3)高效的分类策略-级联结构的设计
HOG Detector
HOG(Histogram of Oriented Gradients)检测器于2005年提出,是当时尺度不变性(Scale Invariant Feature Transform)和形状上下文(Shape Contexts)的重要改进,为了平衡特征不变性(包括平移,尺度,光照等)和非线性(区分不同的对象类别),HOG通过在均匀间隔单元的密集网格上计算重叠的局部对比度归一化来提高检测准确率,因此HOG检测器是基于本地像素块进行特征直方图提取的一种算法,它在目标局部变形和受光照影响下都有很好的稳定性。HOG为后期很多检测方法奠定了重要基础,相关技术被广泛应用于计算机视觉各大应用。
DPM Detector
作为VOC 2007-2009目标检测挑战赛的冠军,DPM(Deformable Parts Model)是目标检测传统算法中当之无愧的SOTA(State Of Art)算法。DPM于2008年提出,相比于HOG,DPM做了很多改进,因此该算法可以看作HOG的延伸算法。DPM算法由一个主过滤器(Root-filter)和多个辅过滤器(Part-filters)组成,通过硬负挖掘(Hard negative mining),边框回归(Bounding box regression)和上下文启动(Context priming)技术改进检测精度。作为传统目标检测算法SOTA,DPM方法运行速度快,能够适应物体形变,但它无法适应大幅度的旋转,因此稳定性差。
局限性
传统的检测算法的一些缺点如下:
- 识别效果不够好,准确率不高
- 计算量较大,运行速度慢
- 可能产生多个正确识别的结果
Anchor-Based中的Two-stage目标检测算法
基于手工提取特征的传统目标检测算法进展缓慢,性能低下。直到2012年卷积神经网络(Convolutional Neural Networks,CNNs)的兴起将目标检测推向了新的台阶。基于CNNs的目标检测算法主要有两条技术发展路线:anchor-based和anchor-free方法,而anchor-based方法则包括一阶段和二阶段检测算法(二阶段目标检测算法一般比一阶段精度高,但一阶段检测算法速度会更快)。
Two-stage算法主要分为以下两个阶段:
Stage1:从图像中生成region proposals
Stage2:从region proposals生成最终的物体边框
RCNN
论文链接:RCNN
代码链接:https://github.com/rbgirshick/rcnn

【简介】 RCNN首先通过选择性搜索算法Selective Search从一组对象候选框中选择可能出现的对象框,然后将这些选择出来的对象框中的图像resize到某一固定尺寸的图像,并输入到CNN模型(经过ImageNet数据集上训练过的CNN模型,如AlexNet)特征提取,最后将提取出的特征送入SVM分类器来预测该对象框中的图像是否存在待检测目标,并进一步预测该检测目标属于哪一类。
【性能】 RCNN算法在VOC-07数据集上取得了非常显著的效果,平均精度由33.7%(DPM-V5,传统检测的SOTA算法)提升到58.5%。相比于传统检测算法,基于深度学习的检测算法在精度上取得了质的飞跃。
【不足】 重叠框(一张图片大约2000多个候选框)特征的冗余计算使得整个网络的检测速度变得很慢(使用GPU的情况下检测一张图片大约需要14s)。
为了减少大量重叠框带来的冗余计算,K.He等人提出了SPPNet
SPPNet
论文链接:SPPNet
代码链接:GitHub - yifanjiang97/sppnet-pytorch: A simple Spatial Pyramid Pooling layer which could be added in CNN

【简介】 SPPNet提出了一种空间金字塔池化层(Spatial Pyramid Pooling Layer,SPP)。它的主要思路是对于一副图像分成若干尺度的图像块(比如一副图像分成1份,4份,8份等),然后对每一块提取的特征融合在一起,从而兼顾多个尺度的特征。SPP使得网络在全连接层之前能生成固定尺度的特征表示,而不管输入图像尺寸如何。当时用SPP网络进行目标检测时,整个图像只需要计算一次即可生成相应的特征图,不管候选框尺寸如何,经过SPP之后,都能生成固定尺寸的特征表示图,这避免了卷积特征图的重复计算。
【性能】 相比于RCNN算法,SPPNet在Pascal-07数据集上不牺牲检测精度(VOC-07,mAP=59.2%)的情况下,推理速度提高了20多倍。
【不足】 与RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征,这需要巨大的存储空间,并且多阶段训练的流程也很繁琐。除此之外,SPPNet只对全连接层进行微调,而忽略了网络其他层的参数。
为了解决以上存在的一些不足,2015年R.Girshick等人提出Fast RCNN
Fast RCNN
论文链接:https://openaccess.thecvf.com/content_iccv_2015/papers/Girshick_Fast_R-CNN_ICCV_2015_paper.pdf
代码链接:rbgirshick/fast-rcnn: Fast R-CNN (github.com)

【简介】 Fast RCNN是RCNN和SPPNet的改进版,该网络使得我们可以可以在相同的网络配置下同时训练一个检测器和边框回归器。该网络首先输入图像,图像被传递到CNN中提取特征,并返回感兴趣的区域RoI,之后在RoI上运行RoI池化层以保证每个区域的尺寸相同,最后这些区域的特征被传递到全连接层的网络中进行分类,并用Softmax和线性回归层同时返回边界框。
【性能】 Fast RCNN在VOC-07数据集上将检测精度mAP从58.5%提高到70.0%,检测速度比RCNN提高了200倍。
【不足】 FAST RCNN仍然选择用选择性搜索算法来寻找感兴趣的区域,这一过程通常比较慢,与RCNN不同的是,FAST RCNN处理一张图片大约需要2s,但是在大型真实数据集上,这种速度仍然不够理想。
问题来了:可不可以直接使用CNN模型来直接生成候选框?基于此Faster RCNN的提出完美解决了这一问题
Faster RCNN
论文链接:https://arxiv.org/pdf/1506.01497.pdf
代码链接:GitHub - jwyang/faster-rcnn.pytorch: A faster pytorch implementation of faster r-cnn

【简介】 Faster RCNN是第一个端到端,最接近实时性能的深度学习检测算法,该网络的主要创新点就是提出了区域选择网络用于生成候选框,能极大提升检测框的生成速度。该网络首先输入图像到卷积网络中,生成该图像的特征映射。在特征映射上应用Region Proposal Network,返回object proposals和相应分数。应用RoI池化层,将所有的proposals修正到同样尺寸。最后将proposals传递到全连接层,生成目标物体的边界框。
【性能】 该网络在当时VOC-07,VOC-12和COCO数据集上实现了SOTA精度,其中COCO mAP@.5=42.7%,COCO mAP@[.5,.95]=21.9%,VOC07 mAP=73.2%,VOC12 mAP=70.4,17fps with ZFNet
【不足】 虽然Faster RCNN的精度更高,速度更快,也更接近于实时性能,但它在后续的检测阶段中仍存在一些计算冗余;除此之外,如果IOU阈值设置的低,会引起噪声检测的问题,如果IOU设置的高,则会引起过拟合。
FPN
论文链接:https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf
代码链接:jwyang/fpn.pytorch: Pytorch implementation of Feature Pyramid Network (FPN) for Object Detection (github.com)

【简介】 2017年,T.-Y.Lin等人在Faster RCNN的基础上进一步提出了特征金字塔网络FPN(Feature Pyramid Networks)技术。在FPN技术出现之前,大多数检测算法的检测头都位于网络的最顶层(最深层),虽说最深层的特征具备更丰富的语义信息,更有利于物体分类,但更深层的特征图由于空间信息的缺乏不利于物体定位,这大大影响了目标检测的定位精度。为了解决这一矛盾,FPN提出了一种具有横向连接的自上而下的网络架构,用于在所有具有不同尺度的高底层都构筑出高级语义信息。FPN的提出极大促进了检测网络精度的提高(尤其是对于一些待检测物体尺度变化大的数据集有非常明显的效果)。
【性能】 将FPN技术应用于Faster RCNN网络之后,网络的检测精度得到了巨大提高(COCO mAP@.5=59.1%, COCO mAP@[.5,.95]=36.2%),再次成为当前的SOTA检测算法。此后FPN成为了各大网络(分类,检测与分割)提高精度最重要的技术之一。
Cascade RCNN
论文链接:https://openaccess.thecvf.com/content_cvpr_2018/papers/Cai_Cascade_R-CNN_Delving_CVPR_2018_paper.pdf
代码链接:zhaoweicai/cascade-rcnn: Caffe implementation of multiple popular object detection frameworks (github.com)

【简介】 Faster RCNN完成了对目标候选框的两次预测,其中RPN一次,后面的检测器一次,而Cascade RCNN则更进一步将后面检测器部分堆叠了几个级联模块,并采用不同的IOU阈值训练,这种级联版的Faster RCNN就是Cascade RCNN。通过提升IoU阈值训练级联检测器,可以使得检测器的定位精度更高,在更为严格的IoU阈值评估下,Cascade R-CNN带来的性能提升更为明显。Cascade RCNN将二阶段目标检测算法的精度提升到了新的高度。
【性能】 Cascade RCNN在COCO检测数据集上,不添加任何Trick即可超过现有的SOTA单阶段检测器,此外使用任何基于RCNN的二阶段检测器来构建Cascade RCNN,mAP平均可以提高2-4个百分点。
Anchor-based中的one-stage目标检测算法

YOLO v1
论文链接:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
代码链接:abeardear/pytorch-YOLO-v1: an experiment for yolo-v1, including training and testing. (github.com)
【概述】
以往的二阶段检测算法,如Faster-RCNN,在检测时需要经过两步:边框回归和softmax分类。由于大量预选框的生成,该方法检测精度较高,但实时性较差。
鉴于此,YOLO之父Joseph Redmon创新性的提出了通过直接回归的方式获取目标检测的具体位置信息和类别分类信息,极大的降低了计算量,显著提升了检测的速度,达到了45FPS(Fast YOLO版本达到了155FPS)。
【思路】
- 将输入图片缩放至448×448×3
- 经过卷积网络backbone提取特征图
- 将提取到的特征图送入两层全连接层,最终输出7×7×30大小的特征图
更进一步讲,就是将输入的图片整体划分为SxS的网格(例如:7x7),物体中心落在哪一个格子中,那么该格子就负责该物体的检测,每一个格子预测B个边框,输出S×S(B×5+C)。其中5为一个五元组(c,x,y,w,h),分别为confidence置信度,x、y为边框坐标,w、h为边框高和宽;C为class个数,表示为one-hot形式

对于YOLOv1而言,常用的是7x7的网格划分,预测2个边框,输出7x7x30,30个通道包含每个类别的概率+边框置信度+边框位置信息。

【网络结构】
骨干网络:GoogLeNet网络构成:24个卷积层+2个全连接层值得注意的是:YOLOv1版本在第一个卷积层使用的是7x7卷积。

【优势和不足】
(1)优势:与二阶段检测算法相比,利用直接回归的方式,大大缩小了计算量,提升了运行速度。
(2)不足:每一个网格仅2个预测框,当存在多物体密集挨着的时候或者小目标的时候,检测效果不好。
YOLO v2
【概述】
针对YOLOv1的问题,YOLO之父Joseph Redmon不甘屈服,对v1版本进行了大刀阔斧的改革,继而提出了YOLOv2网络,重要改革举措包括:
-
更换骨干网络;
-
引入PassThrough;
-
借鉴二阶段检测的思想,添加了预选框。
【思路】
YOLOv2检测算法是将图片输入到darknet19网络中提取特征图,然后输出目标框类别信息和位置信息。
【网络结构】
骨干网络:Darknet-19,如下图所示(针对1000类别的分类任务):

只不过对于检测任务而言,需要使用3个3x3卷积(输出通道1024)取代上表中最后的卷积层,再添加passthrough操作后,进行输出。值得注意的是:已不再使用7x7这样的大卷积核。
trick1: PassThrough操作
该方法将28x28x512调整为14x14x2048,后续v5版本中的Focus操作类似该操作。将生成的14x14x2048与原始的14x14x1024进行concat操作。
trick2: 引入anchor,调整位置预测为偏移量预测借鉴了Faster-RCNN的思想,引入了anchor,将目标框的位置预测由直接预测坐标调整为偏移量预测,大大降低了预测难度,提升了预测准确性。

【优势与不足】
(1)优势:利用passthrough操作对高低层语义信息进行融合,在一定程度上增强了小目标的检测能力。采用小卷积核替代7x7大卷积核,降低了计算量。同时改进的位置偏移的策略降低了检测目标框的难度。
(2)尚未采用残差网络结构。且当存在多物体密集挨着的时候或者小目标的时候,检测效果有待提升。
YOLO v3
【概述】
针对YOLOv2的问题,YOLO之父Joseph Redmon决定深化改革。俗话说“他山之石,可以攻玉”,于是乎吸收当下较好的网络设计思想,引入了残差网络模块。重要深化改革的举措:
-
在darknet19的基础上推陈出新,引入残差,并加深网络深度,提出了Darkent53。
-
借鉴了特征金字塔的思想,在三个不同的尺寸上分别进行预测。
【思路】
YOLOv3检测算法是将图片输入到darknet53网络中提取特征图,然后借鉴特征金字塔网络思想,将高级和低级语义信息进行融合,在低、中、高三个层次上分别预测目标框,最后输出三个尺度的特征图信息(52×52×75、26×26×75、13×13×75)。

其中, 52×52 大小的特征图负责检测小目标, 26×26大小的特征图负责检测中目标, 13×13大小的特征图负责检测大目标。在训练之前,预先通过聚类的方式生成大、中、小三个尺寸的预选框,共9个。预测时最终会输出3x(20+1+4)的数据。一个目标框的输出数据如下:

【网络结构】
骨干网络:Darknet-53


tricks:特征金字塔 该版本借鉴了特征金字塔的思想,只不过与普通的FPN相比略有不同。第一:选择融合的层不同。第二:融合方式不同。对于普通FPN而言,是将高级语义的小尺寸特征图上采样后与上一层进行逐像素相加的融合,融合后尺寸大小和通道数保持不变。而对于YOLOv3而言,是将高级语义的小尺寸特征图上采样到SxS后,选择前面的同为SxS的特征图进行通道方向拼接的融合,融合后,尺寸大小不变但通道数为两者之和。
【优势】
基本解决了小目标检测的问题,在速度和精度上实现了较好的平衡。
YOLO v4
【概述】
Alexey Bochkovskiy对YOLOv3进行了升级改造,核心思想与之前基本一致,不过从数据处理、主干网络、网络训练、激活函数、损失函数等方面对子结构进行了大量的改进。
【思路】
YOLOv4检测算法的基本流程与v3类似,重要升级举措包括:
- 将CSP结构融入Darknet53中,生成了新的主干网络CSPDarkent53
- 采用SPP空间金字塔池化来扩大感受野
- 在Neck部分引入PAN结构,即FPN+PAN的形式
- 引入Mish激活函数
- 引入Mosaic数据增强
- 训练时采用CIOU_loss ,同时预测时采用DIOU_nms
【网络结构】
骨干网络: CSPDarknet53(含spp)Neck: FPN+PAN
检测头:同v3版本

tricks1:输入数据采用Mosaic数据增强
借鉴了2019年CutMix的思路,并在此基础上进行了拓展,Mosaic数据增强方式采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。从而对小目标的检测起到进一步的提升的作用。

tricks2:修改骨干网络为CSPDarknet53
借鉴了2019CSPNet的经验,并结合先前的Darkent53,获得了新的骨干网络CSPDarknet53。在CSPNet中,存在如下操作,即:进入每个stage先将数据划分为两部分,如下图中的part1、part2,区别在于CSPNet中直接对通道维度进行划分,而YOLOv4应用时是利用两个1x1卷积层来实现的。两个分支的信息在交汇处进行Concat拼接。

**tricks3:**引入spp空间金字塔池化模块
引入SPP结构来增加感受野,采用1x1、5x5、9x9、13x13的最大池化的方式,进行多尺度融合,输出按照通道进行concat融合。类似于语义分割网络PSPNet中的PPM模块。

tricks4:在Neck部分采用FPN+PAN的结构
借鉴2018年图像分割领域PANet, 相比于原始的PAN结构,YOLOV4实际采用的PAN结构将addition的方式改为了concatenation。如下图:

由于FPN结构是自顶向下的,将高级特征信息以上采样的方式向下传递,但是融合的信息依旧存在不足,因此YOLOv4在FPN之后又添加了PAN结构,再次将信息从底部传递到顶部,如此一来,FPN自顶向下传递强语义信息,而PAN则自底向上传递强定位信息,达到更强的特征聚合效果。整个NECK结构如下图所示:

【优势】
对比v3和v4版本,在COCO数据集上,同样的FPS等于83左右时,Yolov4的AP是43,而Yolov3是33,直接上涨了10个百分点。
YOLO v5
【简述】
YOLOv5版本 UltralyticsLLC 公司推出的,是在YOLOv4的基础上做了少许的修补,由于改进比较小,仅做简单介绍。改进譬如:
-
将v4版本骨干网络中的csp结构拓展到了NECK结构中。
-
增加了FOCUS操作,但是后续6.1版本中又剔除掉了该操作,使用一个6x6的卷积进行了替代。
-
使用SPPF结构代替了SPP。
【思路】
YOLOv5检测算法的思路与v4基本一致,此处不再赘述。
【网络结构】
骨干网络: CSPDarknet53(含SPPF)
Neck: FPN+PAN
检测头:同v3版本
tricks1:SPPF
主要区别就是MaxPool由原来的并行调整为了串行,值得注意的是:串行两个 5 x 5 大小的 MaxPool 和一个 9 x 9 大小的 MaxPool 是等价的,串行三个 5 x 5 大小的 MaxPool 层和一个 13 x 13 大小的 MaxPool 是等价的。虽然并行和串行的效果一样,但是串行的效率更高,降低了耗时。

tricks2:自适应锚框计算
比较简单,就是把锚框的聚类改为了使用程序进行自适应计算,此处就不再赘述了。
tricks3:Focus操作 后续版本剔除了该操作
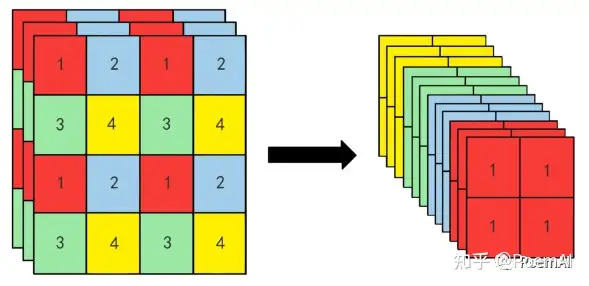
YOLO v6
【概述】
YOLOv6是由美团推出的,所做的主要工作是为了更加适应GPU设备,将2021年的RepVGG结构引入到了YOLO。思路比较简单,本文仅做少许介绍。
【思路】
YOLOv6检测算法的思路类似YOLOv5(backbone+neck)+YOLOX(head)
主要改动:
-
骨干网络由CSPDarknet换为了EfficientRep
-
Neck是基于Rep和PAN构建了Rep-PAN
-
检测头部分模仿YOLOX,进行了解耦操作,并进行了少许优化。
【网络结构】
骨干网络: EfficientRep
Neck: FPN+RepPAN
检测头:类似YOLOX
tricks1:引入RepVGG
按照RepVGG的思路,为每一个3x3的卷积添加平行了一个1x1的卷积分支和恒等映射分支,然后在推理时融合为3x3的结构,这种方式对计算密集型的硬件设备会比较友好。

tricks2:骨干网络EfficientRep
把backbone中stride=2的卷积层换成了stride=2的RepConv层,并且也将CSP-Block修改为了RepBlock。

tricks3:Neck中引入Rep
为了进一步降低硬件上的耗时,将PAN中的CSP-Block替换为RepBlock, 从而生成了Rep-PAN结构。
tricks4:对检测头解耦并重新设计了高效的解耦头为了加快收敛速度和降低检测头复杂度,YOLOv6模仿YOLOX对检测头进行了解耦,分开了目标检测中的边框回归过程和类别分类过程。 由于YOLOX的解耦头中,新增了两个额外的3x3卷积,会在一定程度增加运算的复杂度。鉴于此,YOLOv6基于Hybrid Channels的策略重新设计出了一个更高效的解耦头结构。在不怎么改变精度的情况下降低延时,从而达到了速度与精度的权衡。

【优势】
对耗时做了进一步的优化,进一步提升YOLO检测算法性能。




















































































































